Ivan Gento Pariente, International Marketing Manager Synology, spiega come l’azienda, con l’aiuto dell’intelligenza artificiale abbia migliorato di 20 volte l’efficienza del customer service.
Con 13 milioni di installazioni in tutto il mondo, Synology gestisce ogni anno circa 280.000 ticket d’assistenza che spaziano da semplici richieste di informazioni sui prodotti a complesse consulenze in ambienti IT aziendali. Per creare un’esperienza di customer service rapida e di qualità, quattro anni fa l’azienda ha dato il via a un progetto che prevedeva un team d’intelligenza artificiale e l’uso di tecniche di apprendimento automatico per consigliare agli utenti soluzioni in linea con le loro richieste. Un approccio che consente di risolvere rapidamente circa 50.000 casi di assistenza tecnica ogni anno.
Poi è arrivata l’ascesa dei grandi modelli linguistici (LLM), come GPT-3 nel 2020 e ChatGPT alla fine del 2022, che hanno rivoluzionato il settore dell’elaborazione del linguaggio naturale. Questi modelli hanno dimostrato capacità di comprensione e di generazione di testi senza precedenti, aprendo nuove possibilità di miglioramento dei sistemi di assistenza clienti.
La chiave per un migliore servizio clienti? L’adozione congiunta di LLM e RAG
Sebbene i modelli linguistici di grandi dimensioni abbiano guadagnato una notevole popolarità, non sono sufficienti a risolvere i problemi di assistenza. Le ragioni sono diverse: innanzitutto i dati per addestrare i LLM includono un mix di fonti, come forum di terze parti, articoli obsoleti e contenuti generati dagli utenti, che potrebbero non riflettere sempre le informazioni più attuali o accurate.
Inoltre, questi modelli possono anche faticare a rispondere a richieste uniche che necessitano di una comprensione specifica. Quando un utente presenta un problema, dobbiamo decidere se rispondere in base alle informazioni fornite o chiedere maggiori dettagli determinando quali domande è opportuno porre. Questo approccio richiede non solo la comprensione del contesto del problema, ma anche una profonda conoscenza delle pratiche di assistenza e degli eventuali limiti di Synology.
È qui che la RAG (Retrieval-Augmented Generation) rappresenta un’ottima soluzione. La RAG è una tecnica ampiamente utilizzata per ottimizzare l’accuratezza dell’output di un LLM: recupera dati da database esterni autorevoli per fornire informazioni contestuali accurate che l’intelligenza artificiale utilizza per generare risposte adeguate. Questo approccio aiuta a mantenere i risultati accurati e pertinenti e a garantire che le risposte siano conformi alle policy interne.
Grande attenzione alla privacy dei dati
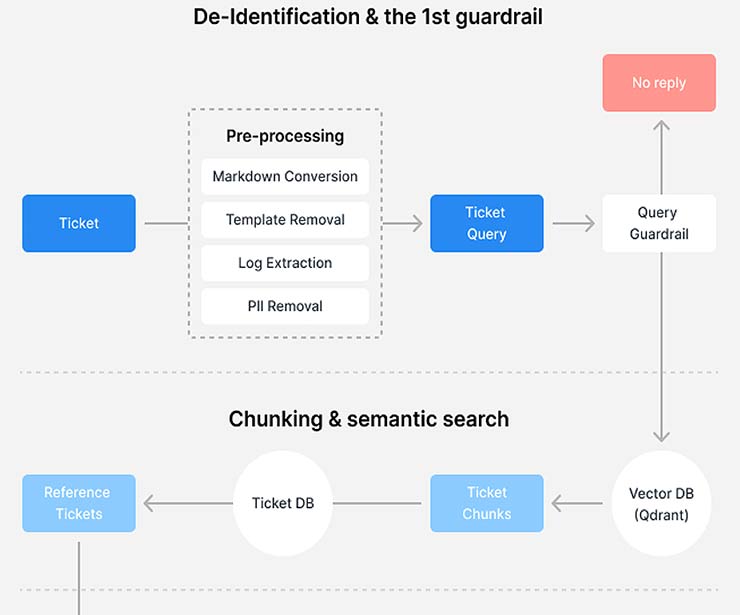
Il nostro sistema di assistenza RAG si basa su un’architettura in quattro fasi progettata per garantire la privacy, l’accuratezza e l’efficienza dei clienti. Il processo inizia con la creazione di un database RAG, in cui vengono utilizzati i dati dell’assistenza tecnica da un anno a questa parte. Questa fase cruciale comprende un accurato processo di de-identificazione per proteggere la privacy dei nostri clienti.
Dopo la de-identificazione, vengono eseguiti il chunking e l’indicizzazione dei dati per un’elaborazione più efficiente in fase di creazione del nostro database RAG. Inoltre, applichiamo l’embedding semantico a questi chunk, abilitando ricerche avanzate di similarità semantica attraverso l’identificazione e il recupero di contenuti rilevanti. In base alla nostra esperienza, è meglio conservare più dati contestuali quando si esegue il chunking, consentendo una sovrapposizione tra ogni segmento di dati. Questo approccio porta a risultati di ricerca più in linea con l’intento del cliente.
Insegnare all’intelligenza artificiale a “capire” le esigenze dei clienti
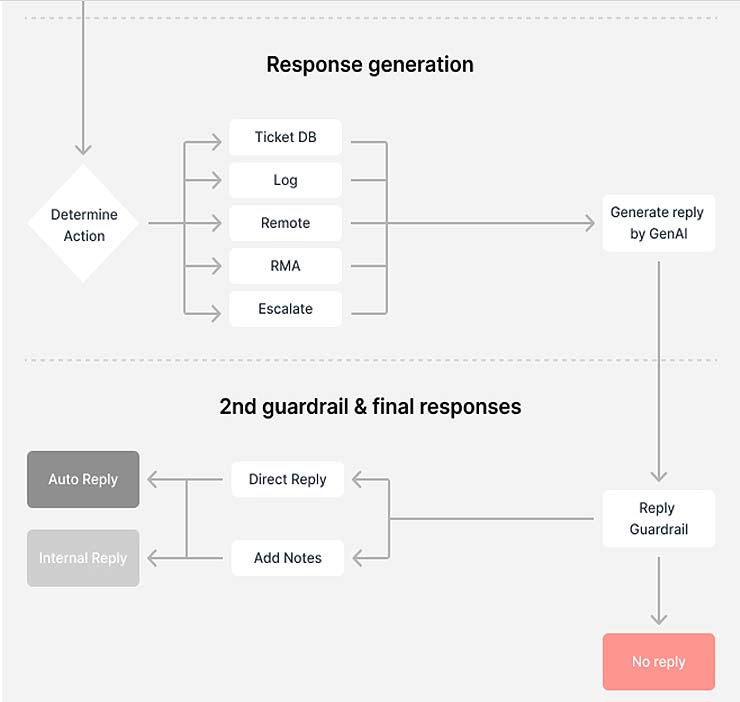
La fase successiva prevede l’elaborazione di nuovi ticket d’assistenza. Quando un cliente invia un ticket, innanzitutto eseguiamo la de-identificazione per anonimizzare le informazioni sensibili e proteggere la sua privacy. Quindi analizziamo il ticket per capire le richieste del cliente e determinare se è necessaria una risposta dell’intelligenza artificiale. Ad esempio, supponiamo che il ticket di assistenza richieda l’intervento di un consulente del supporto tecnico, come avviene quando un cliente richiede attivamente la diagnosi della connessione remota o la risoluzione dei problemi. In questo caso, non è necessario che l’intelligenza artificiale fornisca una risposta.
La parte fondamentale della fase di analisi dell’intento risiede nei criteri di risposta, in quanto è fondamentale definire le strategie di risposta del sistema per i diversi intenti del cliente e determinare quando il sistema deve passare a uno specialista, chiedere al cliente ulteriori informazioni o estrarre e generare direttamente contenuti dal database.
Recuperare le informazioni rilevanti dal database RAG
Una volta che l’IA ha compreso meglio il contesto, la terza fase prevede la creazione di un solido meccanismo di ricerca. La domanda del cliente viene riscritta per ottimizzare l’estrazione di informazioni dal nostro database RAG. Utilizziamo anche un metodo di ricerca semantica che ci permette di estrarre vecchi ticket pertinenti e di fornire un contesto più ricco per generare le risposte.
La qualità dei risultati della ricerca dipende fortemente dal nostro approccio alla segmentazione dei dati. Per risolvere questo problema, stiamo sviluppando un modello avanzato di re-ranking che utilizza il deep learning per ricalibrare i risultati della ricerca in base ai punteggi di somiglianza calcolati. Questo ulteriore livello di elaborazione mira a migliorare ulteriormente la pertinenza e l’accuratezza delle informazioni che forniamo, migliorando in ultima analisi la nostra capacità di soddisfare con maggiore precisione le esigenze dei nostri clienti.
Generazione di risposte conformi alle policy e con la supervisione umana
Nella fase finale, generiamo risposte basate sulle informazioni elaborate. Creiamo un prompt utilizzando le necessità analizzate, la domanda riscritta e i dati rilevanti estratti. La risposta generata viene quindi sottoposta a una serie di controlli di policy e a ulteriori guardrail per garantire che non vengano fornite informazioni sensibili come comandi di console, dettagli di accesso remoto o qualsiasi cosa che sia contestualmente accurata ma che potrebbe non essere disponibile o applicabile in determinati scenari. Questi controlli aiutano a rispettare la sicurezza e a mantenere le risposte nell’ambito appropriato del supporto assistito dall’intelligenza artificiale.
Infine, il guardrail aiuta a determinare se le risposte generate sono valide per un parere automatico. Se il guardrail determina che i ticket richiedono l’intervento del personale d’assistenza, presentiamo il suggerimento generato dall’AI al nostro customer service. Il professionista esprime il giudizio finale sull’adeguatezza e l’accuratezza della risposta prima che questa raggiunga il cliente.
Maggiore efficienza e una velocità fino a 20 volte superiore
L’architettura ci permette di incorporare l’intelligenza artificiale generativa mantenendo gli elevati standard di precisione e sicurezza che i nostri clienti si aspettano dall’assistenza Synology. Sfruttando la potenza di LLM e RAG e automatizzando le risposte alle richieste di routine, abbiamo ottenuto tempi di risposta fino a 20 volte più veloci rispetto al passato.
Mentre continuiamo a perfezionare il nostro sistema di assistenza basato sull’intelligenza artificiale, ci concentriamo sul miglioramento dell’accuratezza e della pertinenza delle risposte per i nostri utenti in tutto il mondo. Continueremo a focalizzarci sulla localizzazione delle soluzioni, i problemi comuni e le policy di conformità. Questo approccio garantisce che i suggerimenti generati dall’intelligenza artificiale siano tecnicamente accurati e in linea con le normative e le pratiche locali. Fornendo risposte più accurate, miriamo a liberare una parte del nostro team di assistenza per gestire i problemi più difficili e urgenti che richiedono un tocco umano. Questo ci aiuta a lavorare in modo più efficiente, pur offrendo ai clienti Synology l’assistenza personalizzata e di qualità che si aspettano.