
Rajesh Jain, Product Specialist di Dynatrace, analizza le differenti criticità del cloud in termini di prestazioni e suggerisce il comportamento migliore per garantire disponibilità e prestazioni elevate. I vantaggi maggiori dell’implementazione del cloud sono la facilità d’uso e la flessibilità nell’aggiungere e rimuovere capacità di elaborazione. È possibile allocare dinamicamente le risorse in base ai cambiamenti nei carichi di lavoro, garantendo la flessibilità nella gestione dei costi di elaborazione.
Amazon con AWS Auto Scaling, ad esempio, permette di seguire da vicino la curva di domanda per le applicazioni. Nel caso l’utilizzo della CPU superi il 70% è possibile aggiungere ulteriori istanze EC2 e, allo stesso modo, se l’utilizzo della CPU scende al di sotto di una soglia prestabilita queste istanze si possono facilmente rimuovere. Non è molto diversa la situazione con Rackspace Auto Scale, che può basarsi sulla pianificazione o sugli eventi, per essere preparati ad un traffico intenso durante particolari periodi di vacanze o nelle ore di punta. Anche Microsoft Azure offre la scalabilità per l’applicazione sia in automatico che in base alla pianificazione, con la possibilità di fornire CPU aggiuntiva o aumentare i messaggi in coda sulla macchina di destinazione. Nella piattaforma PAAS Cloud Foundry, infine, scalare in automatico un’applicazione rispetto a centinaia di istanze utilizzando BOSH AutoScaler è facile come definire le regole per scalare in automatico e questo può consente di creare istanze multiple per le applicazioni.
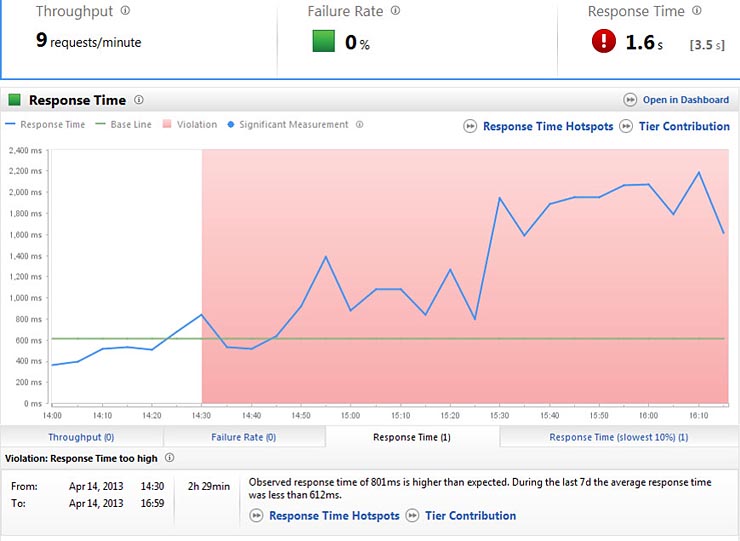
La flessibilità di scala automatica è un beneficio e un aspetto indispensabile in qualsiasi implementazione cloud ma può implicare presto spese aggiuntive. Risorse di calcolo ulteriori significano, infatti, ulteriori costi in un percorso a spirale che rischia di svilupparsi in maniera esponenziale senza affrontare il vero problema:
L’applicazione sta veramente utilizzando le risorse che le sono state dedicate? Abbiamo la giusta visibilità?
Per rispondere a queste domande, abbiamo eseguito un test provando a implementare un’applicazione di ecommerce su piattaforma LAMP con il supporto di alcuni provider cloud. Si è trattato di un negozio online che vende prodotti di elettronica e che ha tutte le funzionalità di un sito di ecommerce classico.
Le transazioni principali che opera sono: registrare un utente, riportare l’ordine, ricevere email, verificare lo stato dell’ordine, registrare la tipologia di pagamento (assegno o vaglia postale). Questa applicazione è preconfezionata con Bitnami e viene eseguita su piattaforma open source LAMP che permette la visualizzazione dell’infrastruttura, che comprende server Web/App e database MySQL su siti cloud multipli negli Stati Uniti e in Europa.
Abbiamo utilizzato Synthetic Monitoring 2.0 per le operazioni principali di script del negozio online. Generando un carico costante di prova abbiamo imitato gli utenti reali provenienti da varie località della backborne attraverso gli ISP. Per misurare la disponibilità e le prestazioni del sito web nel cloud., abbiamo scritto URL singole e test multi step. E, infine, abbiamo fornito la backend della soluzione dynaTrace, distribuendo agenti PHP/web a tutti i livelli dell’applicazione.
Il risultato? Se si tira troppo l’elastico le prestazioni non sono più costanti.
Monitorando le operazioni del sito di ecommerce, è stato possibile scoprire quali fossero le prestazioni reali e la disponibilità del sito rispetto alle diverse aree geografiche, ai differenti ISP e collegare le prestazioni ai provider cloud. Guardando alla CPU/Disk/IO/Network abbiamo notato differenze significative nella capacità dei diversi provider cloud di fornire lo stesso livello di tempi di risposta e di produttività. Il risultato è che il cloud, come un elastico, potenzialmente si può tirare per aumentare la potenza di calcolo in modo da ottenere il massimo delle prestazioni dai diversi fornitori, ma tutto questo ha un costo perché, inevitabilmente, le prestazioni tenderanno a variare e non essere costanti.
Solo una visibilità completa sull’applicazione consente di risolvere questi problemi prestazionali. Il primo passo è, infatti, ottimizzare le proprie applicazioni, prendere come punto di riferimento le loro prestazioni e ottenere la visibilità necessaria per poi arrivare a scalare in automatico, il che può migliorare le prestazioni delle applicazioni anche per affrontare sfide future.
Per ottenere visibilità sulle prestazioni delle applicazioni ospitate nel cloud è necessario adottare strumenti, come quelli usati durante il test. Bisogna partire dall’individuare quali sono i punti dove l’applicazione perde più tempo: se si tratta del front-end, del network o se questo accade nell’ambiente ospitato nel cloud. Ponendo attenzione al flusso end-to-end delle transazioni per identificare i colli di bottiglia, ottimizzando le risorse e l’applicazione.
Quattro sono, in sintesi, i passaggi che a mio avviso è fondamentale seguire per garantire disponibilità e prestazioni elevate alla propria App:
1. Effettuare test prestazionali e di carico proattivi
2. Ottimizzare l’applicazione guadagnando una visibilità end to end
3. Confrontare (provare ad esempio a distribuire la propria App attraverso service provider cloud multipli, effettuate prima il test e vedete chi si comporta meglio)
4. Definite in modo corretto la dimensione delle proprie risorse cloud/ il capacity planning
Certo, i problemi prestazionali si possono sempre risolvere aggiungendo nel cloud delle risorse di elaborazione extra per le proprie App, ma solo adottando questi passaggi sarà possibile colmare il gap della visibilità.





