Antonino Ingargiola, Big Data & ML Engineering Lead di Agile Lab, ci parla di Data Mesh e di come trasformare un’impresa in una Data-Driven Company.
– Diventare una Data-Driven Company non è più un optional per le imprese, ma come si può attuare questo cambio di paradigma?
Per trasformare un’azienda in una Data-Driven Company, si deve partire instaurando una cultura del dato come mezzo per generare valore. ll primo cambiamento necessario è quello di considerare la cura del dato come un centro di profitto, e non di costo. Per fare un esempio, i casi d’uso che impiegano modelli Machine Learning richiedono un processo sperimentale altamente iterativo durante il loro sviluppo, e sono realizzabili solo se le sorgenti dati sono di alta qualità e interoperabili su larga scala.
Nel momento in cui i dati diventano affidabili, tempestivi, documentati, interoperabili e di facile accesso sul piano analitico si creano delle opportunità di creazione del valore dirette, ma anche “emergenti”, dove l’incrocio di fonti diverse genera un valore inatteso. In sostanza, per farsi guidare dai dati è necessario che questi vengano messi al centro della catena del valore. Per tale motivo è più opportuno indicare l’approccio ideale come Data-Centric prima ancora che Data-Driven.
– Data Mesh, quali sono i principi fondanti?
Il paradigma del Data Mesh è un approccio socio-tecnico proposto da Zhamak Dehghani nel 2019, che mira a superare i limiti di scalabilità e velocità di risposta al cambiamento intrinseci in approcci tradizionali di data management, quali data warehousing e data lake. Infatti, a fronte di una sempre crescente mole di dati da sorgenti eterogenee e dal moltiplicarsi dei casi d’uso, un approccio basato su un team centralizzato non scala oltre una certa soglia e diventa inevitabilmente un collo di bottiglia. D’altro canto, senza una governance in grado di imporre regole generali, un data lake degenera facilmente in un data swamp, una “palude” dove i dati sono difficili da trovare e di qualità altamente variabile, rendendo ogni utilizzo molto lento e oneroso.
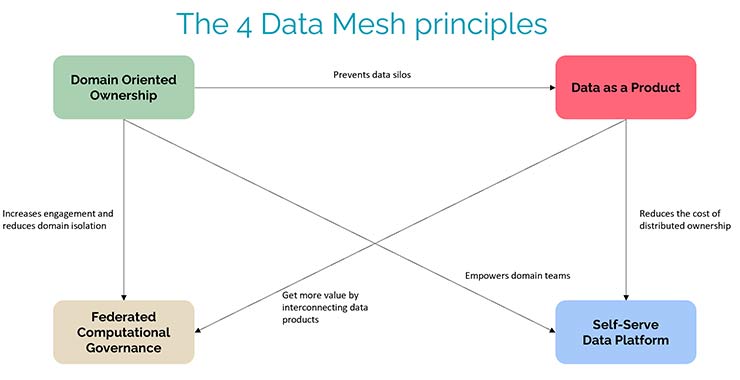
Il paradigma del Data Mesh mira a risolvere questi limiti attraverso quattro pilastri fondanti:
“Domain Ownership”: la stessa divisione usata per i domini di business in una azienda, deve riflettersi anche nell’ownership decentralizzata della gestione dati. Ogni dominio di business deve essere proprietario e gestore dei dati che genera, preoccupandosi di documentarli e pubblicarli, in modo che l’intera organizzazione ne possa trarre profitto. Questo principio allinea l’architettura dati con quella di business e permette di superare i limiti di scalabilità intrinseci in un’architettura centralizzata.
“Data as a Product”: i dati di dominio devono essere pubblicati come veri e propri prodotti su un marketplace. Un prodotto di successo deve essere affidabile e di facile utilizzo. Similmente, un Data Product deve esporre dati di qualità garantita e renderli accessibili attraverso documentazione relativa alla loro struttura e pattern di accesso. In tal modo si abilita un utilizzo self-service da parte di utenti business o da altri Data Product sulla mesh.
“Self-serve data platform”: per consentire a domini di gestire facilmente e in autonomia il ciclo di vita dei Data Product è necessaria una piattaforma dati che automatizzi i processi operativi della mesh. Tale piattaforma rende automatiche operazioni quali provisioning di risorse, deploy di software, gestione di permessi di accesso, pubblicazione su marketplace, e abilita funzioni di discovery e controlli di compliance sull’intera mesh. Lo scopo è abbattere il costo dell’ownership decentralizzata dei dati da parte dei domini, consentendo interoperabilità rispetto delle policy.
“Federated Computational Governance”: se l’ownership sui dati diventa distribuita, la governance diventa federata. Un team di Federated Governance ha lo scopo di garantire interoperabilità e sicurezza della mesh, nonché la sua compliance con le normative in vigore. Le policy definite dalla Federated Governance sono rese “computazionali” dalla piattaforma, che ne esegue un enforcement automatico (“computazionale”). Il team di Federated Governance è composto da rappresentanti di ciascun dominio e altri esperti, ad esempio di sicurezza e compliance. La definizione delle policy avviene attraverso un processo che bilancia le esigenze dei domini con le necessità infrastrutturali della mesh.
Questo paradigma richiede un forte cambiamento organizzativo, soprattutto nella decentralizzazione e integrazione dei team tradizionalmente centralizzati di IT e data management con domini di business cross-funzionali.
– Data Mesh e Data Virtualization, come si sviluppa questo binomio?
I Data Product espongono i dati in modo standardizzato. Un consumer può leggere i dati esposti da un Data Product in modalità self-service e senza necessità di una copia massiva. Grazie alla standardizzazione imposta dalla Federated Governance, viene consentito solo un numero limitato di tecnologie. Ad esempio, i Data Product potrebbero esporre dati in “table format” (in formati quali DeltaLake o Iceberg) oppure in formato “Events” (ad esempio topic Kafka).
Tali tecnologie permettono di leggere o filtrare i dati tramite i principali linguaggi di programmazione, oppure attraverso interfacce SQL-like. Grazie a queste interfacce si moltiplicano le modalità di accesso ai dati, senza richiedere alcuna duplicazione fisica, offrendo al contempo un’elevata flessibilità per diversi casi d’uso. L’alto livello di standardizzazione nell’accesso ai dati esposti dai Data Product riduce la necessità di soluzioni di Data Virtualization. Quest’ultime possono invece risultare vantaggiose per l’ingestione dei dati sulla mesh da sorgenti operazionali che tendono a essere basate su un tecnologie più variegate e spesso legacy.
– Sia il domain-driven design che il Data Mesh sono fattori abilitanti per lo sviluppo ad alte prestazioni all’interno delle aziende che sviluppano software e sono orientate al prodotto. Quali sono i vantaggi di queste architetture per le imprese? Si tratta di una soluzione adatta a tutte le tipologie di imprese?
Il paradigma del Data Mesh prende ispirazione dall’architettura distribuita propria del DDD (Domain Driven Design). Inoltre, l’identificazione di un Data Product nel Data Mesh ripercorre la stessa demarcazione per bounded context tipica del DDD. In modo simile, il Data Mesh richiede una organizzazione distribuita in team di dominio indipendenti che gestiscano il ciclo di vita end-to-end dei loro Data Product attraverso una piattaforma abilitante. L’obiettivo è quello di superare i limiti di scalabilità di un approccio centralizzato.
Entrambi sono utili in aziende complesse ed eterogenee, tipicamente realtà grandi e medio-grandi, che hanno già raggiunto i limiti di scalabilità e di velocità di risposta al cambiamento, che si manifestano sia nello sviluppo di applicazioni e servizi che nell’utilizzo dei dati per fornire servizi sempre più personalizzati e e supportare decisioni strategiche. Per tali realtà, pratiche quali DDD e Data Mesh rappresentano l’approccio ideale.
– Sebbene siano ampiamente discussi nel settore, l’adozione di questi due modelli fondamentali non è così diffusa come dovrebbe. Come potenziarne visibilità e diffusione?
Mentre la pratica del DDD e dell’architettura a microservizi è ben documentata da numerosi casi di successo, per il Data Mesh sono ben poche le risorse autorevoli e gli esempi di realizzazione concreti del paradigma. A fronte di un forte fermento, solo le aziende più audaci hanno iniziato ad abbracciarlo, ed è necessario quindi continuare a divulgare questa pratica dimostrando casi concreti di utilizzo in modo da spingere la prossima fase di adopter a intraprendere questa transizione. Infine, l’emergere di piattaforme di data management a supporto del Data Mesh rappresenterà un fattore catalizzante per abilitare l’adozione di questo paradigma su larga scala.